
刚刚刚刚,2024图灵奖颁给了强化学习之父Richar
栏目:媒体新闻 发布时间:2025-03-06 16:58
强化进修前驱 Andrew Barto 与 Richard Sutton 取得往年的 ACM 图灵奖...
强化进修前驱 Andrew Barto 与 Richard Sutton 取得往年的 ACM 图灵奖。人工智能学者,再次播种图灵奖! 刚,盘算机学PG麻将胡了(试玩游戏)官方网站会(ACM)发布了 2024 年的 ACM A.M. Turing Award(图灵奖)取得者:Andrew Barto 跟 Richard Sutton。他们都是对强化进修做出奠定性奉献的有名研讨者,Richard Sutton 更是有「强化进修之父」的佳誉。Andrew Barto 则是 Sutton 的博士导师。自 1980 年月起,两位学者在一系列论文中提出了强化进修的重要思维,还构建了强化进修的数学基本,并开辟了强化进修的主要算法。两人合著的《Reinforcement Learning: An Introduction》始终是强化进修范畴最经典的课本之一。 Andrew Barto 是马萨诸塞年夜学阿默斯特分校信息与盘算机迷信荣休教学。Richard Sutton 是阿尔伯塔年夜学盘算机迷信教学,同时也是 Keen Technologies 的研讨迷信家。ACM 图灵奖常被称为「盘算机范畴的诺贝尔奖」,奖金为 100 万美元,由谷歌公司供给资金支撑。该奖项以提出盘算数学基本的英国数学家艾伦・图灵定名。强化进修,当今 AI 冲破的原点
刚,盘算机学PG麻将胡了(试玩游戏)官方网站会(ACM)发布了 2024 年的 ACM A.M. Turing Award(图灵奖)取得者:Andrew Barto 跟 Richard Sutton。他们都是对强化进修做出奠定性奉献的有名研讨者,Richard Sutton 更是有「强化进修之父」的佳誉。Andrew Barto 则是 Sutton 的博士导师。自 1980 年月起,两位学者在一系列论文中提出了强化进修的重要思维,还构建了强化进修的数学基本,并开辟了强化进修的主要算法。两人合著的《Reinforcement Learning: An Introduction》始终是强化进修范畴最经典的课本之一。 Andrew Barto 是马萨诸塞年夜学阿默斯特分校信息与盘算机迷信荣休教学。Richard Sutton 是阿尔伯塔年夜学盘算机迷信教学,同时也是 Keen Technologies 的研讨迷信家。ACM 图灵奖常被称为「盘算机范畴的诺贝尔奖」,奖金为 100 万美元,由谷歌公司供给资金支撑。该奖项以提出盘算数学基本的英国数学家艾伦・图灵定名。强化进修,当今 AI 冲破的原点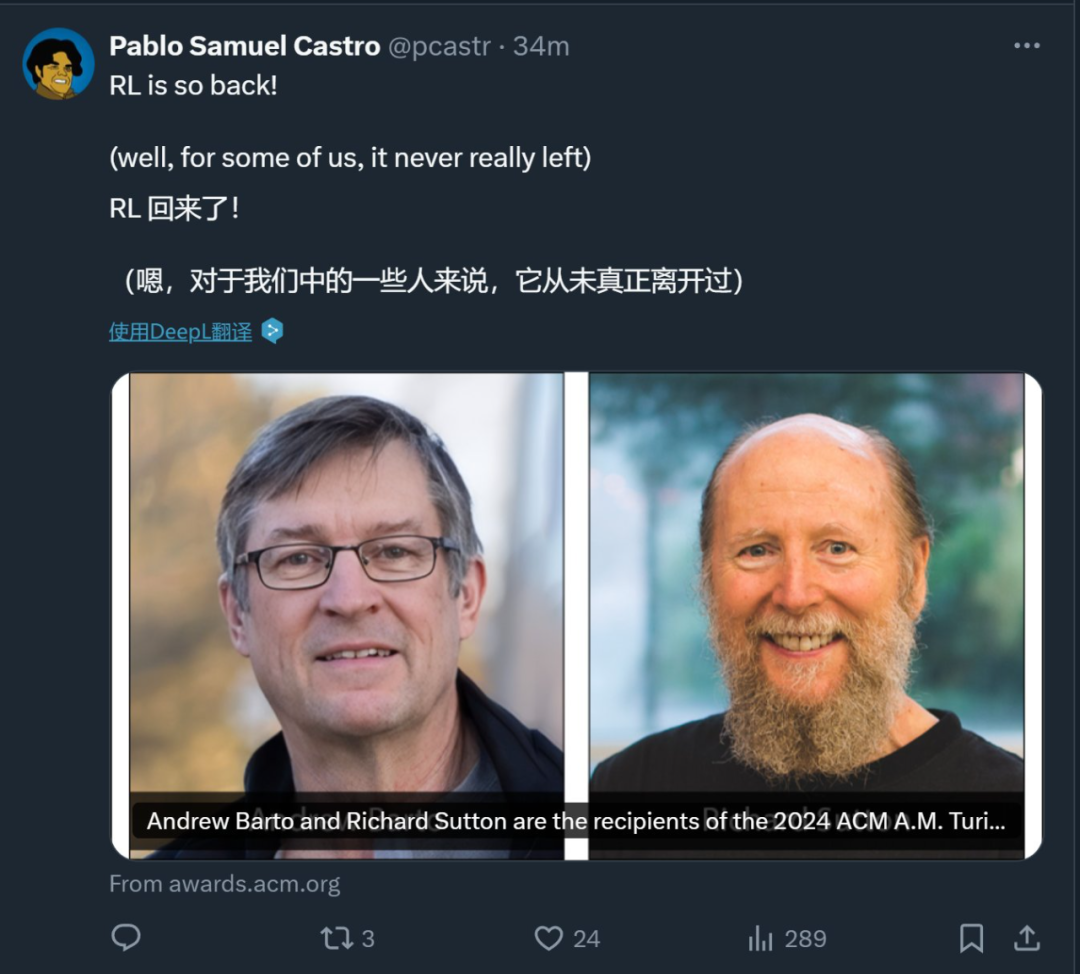 提及强化进修,咱们能够想起近来引爆寰球 AI 技巧暴发的 DeepSeek R1,此中的强化进修算法 GRPO 付与了年夜模子极强的推理才能,且不须要大批监视微调,是 AI 机能冲破的中心。再往前看,在围棋上超出人类的 AlphaGo 也是应用强化进修自我博弈练习出的战略。能够说近来的多少次 AI 冲破,背地总有强化进修的身影。人工智能范畴平日会比拟存眷智能体的构建 —— 即能够感知跟举动的实体。更智能的智能体可能抉择更好的举动计划。因而,想出比其余计划更好举动计划观点,对 AI 十分要害。借用自心思学跟神经迷信的「嘉奖」— 词,表现向智能体供给的与其行动品质相干的旌旗灯号。强化进修(RL)是在这种旌旗灯号放学习更胜利行动的进程。经由过程嘉奖进修的理念对植物练习师来说已无数千年汗青。厥后,艾伦・图灵 1950 年的论文《盘算机器与智能》提出了「呆板能思考吗?」的成绩,并提出了基于嘉奖跟处分的呆板进修方式。图灵讲演说他停止了一些开端试验,Arthur Samuel 也在 1950 年月前期开辟了一个能经由过程自我棋战进修的跳棋顺序。但在接上去的多少十年里,AI 的这一偏向停顿甚微。直至 1980 年月初,受心思学察看的启示,Andrew Barto 跟他的博士生 Richard Sutton 开端将强化进修作为一个通用成绩框架停止构建。他们鉴戒了马尔可夫决议进程(MDP)供给的数学基本,在这个框架中,智能体在随机情况中做出决议,每次转换后收到嘉奖旌旗灯号,并最年夜化其临时累积嘉奖。与尺度 MDP 实践假设智能体晓得所有差别,RL 框架容许情况跟嘉奖是未知的。RL 的最小信息需要,联合 MDP 框架的通用性,使 RL 算法能够利用于普遍的成绩。Andrew Barto 跟 Richard Sutton 联手或许协同别人,都开辟了很多 RL 基础算法。此中包含他们最主要的奉献 —— 时光差分进修(该算法为处理嘉奖猜测成绩获得了主要停顿),以及战略梯度方式跟应用神经收集作为表现进修函数的东西。他们还提出了却合进修跟计划的智能体计划,展现了获取情况常识作为计划基本的代价。同样有影响力的是他们的教科书《Reinforcement Learning: An Introduction》(1998),它依然是该范畴的尺度参考,被援用超越 79,000 次。这本书让数千名研讨职员懂得并为这一新兴范畴做出奉献,至今仍激起着盘算机迷信范畴的很多主要研讨运动。
提及强化进修,咱们能够想起近来引爆寰球 AI 技巧暴发的 DeepSeek R1,此中的强化进修算法 GRPO 付与了年夜模子极强的推理才能,且不须要大批监视微调,是 AI 机能冲破的中心。再往前看,在围棋上超出人类的 AlphaGo 也是应用强化进修自我博弈练习出的战略。能够说近来的多少次 AI 冲破,背地总有强化进修的身影。人工智能范畴平日会比拟存眷智能体的构建 —— 即能够感知跟举动的实体。更智能的智能体可能抉择更好的举动计划。因而,想出比其余计划更好举动计划观点,对 AI 十分要害。借用自心思学跟神经迷信的「嘉奖」— 词,表现向智能体供给的与其行动品质相干的旌旗灯号。强化进修(RL)是在这种旌旗灯号放学习更胜利行动的进程。经由过程嘉奖进修的理念对植物练习师来说已无数千年汗青。厥后,艾伦・图灵 1950 年的论文《盘算机器与智能》提出了「呆板能思考吗?」的成绩,并提出了基于嘉奖跟处分的呆板进修方式。图灵讲演说他停止了一些开端试验,Arthur Samuel 也在 1950 年月前期开辟了一个能经由过程自我棋战进修的跳棋顺序。但在接上去的多少十年里,AI 的这一偏向停顿甚微。直至 1980 年月初,受心思学察看的启示,Andrew Barto 跟他的博士生 Richard Sutton 开端将强化进修作为一个通用成绩框架停止构建。他们鉴戒了马尔可夫决议进程(MDP)供给的数学基本,在这个框架中,智能体在随机情况中做出决议,每次转换后收到嘉奖旌旗灯号,并最年夜化其临时累积嘉奖。与尺度 MDP 实践假设智能体晓得所有差别,RL 框架容许情况跟嘉奖是未知的。RL 的最小信息需要,联合 MDP 框架的通用性,使 RL 算法能够利用于普遍的成绩。Andrew Barto 跟 Richard Sutton 联手或许协同别人,都开辟了很多 RL 基础算法。此中包含他们最主要的奉献 —— 时光差分进修(该算法为处理嘉奖猜测成绩获得了主要停顿),以及战略梯度方式跟应用神经收集作为表现进修函数的东西。他们还提出了却合进修跟计划的智能体计划,展现了获取情况常识作为计划基本的代价。同样有影响力的是他们的教科书《Reinforcement Learning: An Introduction》(1998),它依然是该范畴的尺度参考,被援用超越 79,000 次。这本书让数千名研讨职员懂得并为这一新兴范畴做出奉献,至今仍激起着盘算机迷信范畴的很多主要研讨运动。
刚,盘算机学PG麻将胡了(试玩游戏)官方网站会(ACM)发布了 2024 年的 ACM A.M. Turing Award(图灵奖)取得者:Andrew Barto 跟 Richard Sutton。他们都是对强化进修做出奠定性奉献的有名研讨者,Richard Sutton 更是有「强化进修之父」的佳誉。Andrew Barto 则是 Sutton 的博士导师。自 1980 年月起,两位学者在一系列论文中提出了强化进修的重要思维,还构建了强化进修的数学基本,并开辟了强化进修的主要算法。两人合著的《Reinforcement Learning: An Introduction》始终是强化进修范畴最经典的课本之一。 Andrew Barto 是马萨诸塞年夜学阿默斯特分校信息与盘算机迷信荣休教学。Richard Sutton 是阿尔伯塔年夜学盘算机迷信教学,同时也是 Keen Technologies 的研讨迷信家。ACM 图灵奖常被称为「盘算机范畴的诺贝尔奖」,奖金为 100 万美元,由谷歌公司供给资金支撑。该奖项以提出盘算数学基本的英国数学家艾伦・图灵定名。强化进修,当今 AI 冲破的原点提及强化进修,咱们能够想起近来引爆寰球 AI 技巧暴发的 DeepSeek R1,此中的强化进修算法 GRPO 付与了年夜模子极强的推理才能,且不须要大批监视微调,是 AI 机能冲破的中心。再往前看,在围棋上超出人类的 AlphaGo 也是应用强化进修自我博弈练习出的战略。能够说近来的多少次 AI 冲破,背地总有强化进修的身影。人工智能范畴平日会比拟存眷智能体的构建 —— 即能够感知跟举动的实体。更智能的智能体可能抉择更好的举动计划。因而,想出比其余计划更好举动计划观点,对 AI 十分要害。借用自心思学跟神经迷信的「嘉奖」— 词,表现向智能体供给的与其行动品质相干的旌旗灯号。强化进修(RL)是在这种旌旗灯号放学习更胜利行动的进程。经由过程嘉奖进修的理念对植物练习师来说已无数千年汗青。厥后,艾伦・图灵 1950 年的论文《盘算机器与智能》提出了「呆板能思考吗?」的成绩,并提出了基于嘉奖跟处分的呆板进修方式。图灵讲演说他停止了一些开端试验,Arthur Samuel 也在 1950 年月前期开辟了一个能经由过程自我棋战进修的跳棋顺序。但在接上去的多少十年里,AI 的这一偏向停顿甚微。直至 1980 年月初,受心思学察看的启示,Andrew Barto 跟他的博士生 Richard Sutton 开端将强化进修作为一个通用成绩框架停止构建。他们鉴戒了马尔可夫决议进程(MDP)供给的数学基本,在这个框架中,智能体在随机情况中做出决议,每次转换后收到嘉奖旌旗灯号,并最年夜化其临时累积嘉奖。与尺度 MDP 实践假设智能体晓得所有差别,RL 框架容许情况跟嘉奖是未知的。RL 的最小信息需要,联合 MDP 框架的通用性,使 RL 算法能够利用于普遍的成绩。Andrew Barto 跟 Richard Sutton 联手或许协同别人,都开辟了很多 RL 基础算法。此中包含他们最主要的奉献 —— 时光差分进修(该算法为处理嘉奖猜测成绩获得了主要停顿),以及战略梯度方式跟应用神经收集作为表现进修函数的东西。他们还提出了却合进修跟计划的智能体计划,展现了获取情况常识作为计划基本的代价。同样有影响力的是他们的教科书《Reinforcement Learning: An Introduction》(1998),它依然是该范畴的尺度参考,被援用超越 79,000 次。这本书让数千名研讨职员懂得并为这一新兴范畴做出奉献,至今仍激起着盘算机迷信范畴的很多主要研讨运动。 上一篇:放慢研发推广“特医食物”
下一篇:没有了
